Bienvenue !
Pierre-Julien VILLOUD

La suite Elastic
Pour répondre à chacun de ces cas d'utilisation, nous parlerons de la suite Elastic, comprenant (entre autres...) Elasticsearch, Logstash, Kibana et Beats.

L'objectif de ce cours n'est pas de vous présenter en détails l'ensemble des fonctionnalités (cela demanderait plus de temps !), mais de vous montrer les principes de fonctionnement et quelques cas d'utilisation concrets afin de mieux appréhender ces outils.
Le moteur de recherche
A l'heure du Big Data, la recherche est un enjeu très important et les recherches simples ne sont plus suffisantes.
Il faut pouvoir rechercher rapidement dans un ensemble de données conséquent et varié.
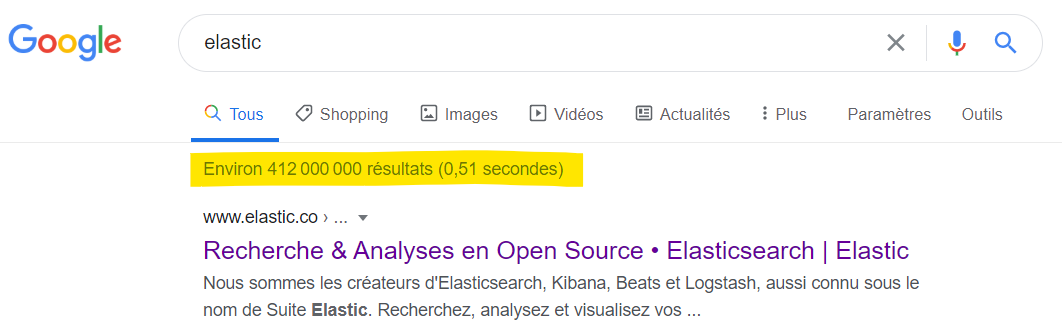
Il faut pouvoir rechercher approximativement et proposer des corrections automatiques.
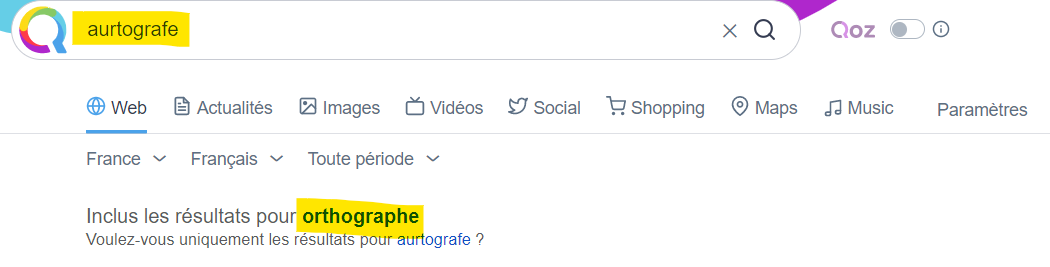
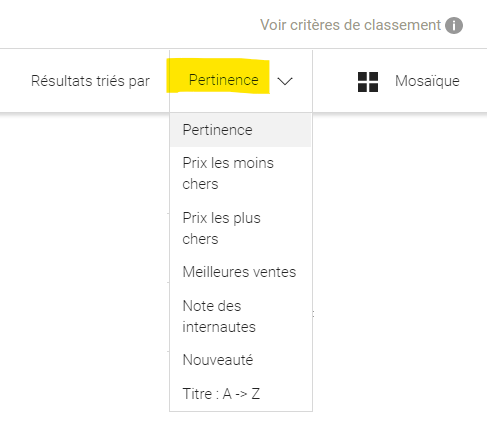
Il faut pouvoir trier selon divers critères des résultats avec une notion de pertinence.
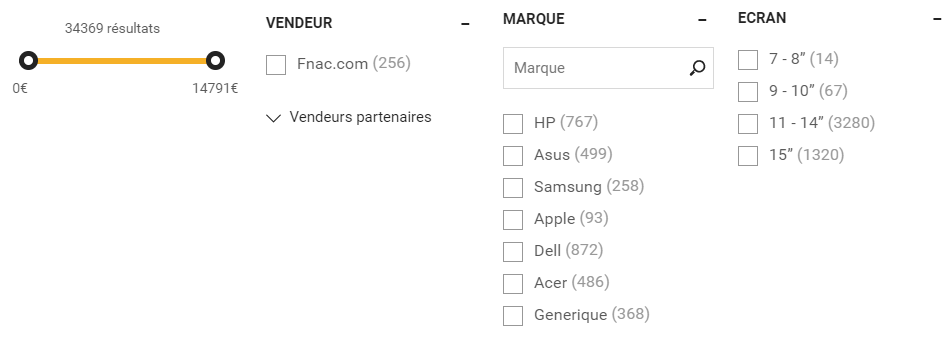
Il faut pouvoir filtrer ou regrouper les résultats.
Il faut pouvoir proposer des suggestions pour améliorer la recherche.
Présentation d'Elasticsearch
Elasticsearch est un moteur de recherche et d'analyse de texte Open Source basé sur le moteur de recherche Apache Lucene. Il est la partie centrale de la suite Elastic. Il est également parmi les moteurs de base de données NoSql les plus populaires.

Elasticsearch fournit un ensemble de services web REST permettant d'intéragir avec lui et fonctionne en cluster.
Concepts
Elasticsearch est un moteur de recherche riche en fonctionnalités mais relativement complexe. L'objectif ici est de comprendre les concepts clés permettant de l'utiliser dans le cadre de la suite Elastic.

Voyons en détail chacun de ces concepts.
Communication
La manière la plus simple de communiquer avec un cluster Elasticsearch est via son interface REST. Accessible par défaut sur le port
9200, elle permet de configurer le cluster et ses différents noeuds, d'effectuer toutes les opérations de CRUD sur les index ou les documents et d'effectuer tout type de recherche.

De nombreux clients Elasticsearch existent (notamment un présent dans Kibana) permettant de rendre l'interface plus accessible. La documentation complète de l'API est disponible ici.
Agréger
Les agrégations permettent de présenter les données regroupées selon certains champs. On parle de facettes Il est alors possible de classer et analyser les résultats retournés sous diverses formes (diagrammes...) et améliorer la navigation en indiquant clairement les filtrages possibles.
Très intéressant lorsqu'on recherche parmi un catalogue de produits par exemple, ce mécanisme s'avérera également pratique dans le cadre du monitoring d'applications
La suite Beats
Beats représente un ensemble de modules permettant de récupérer des données de sources diverses afin de les envoyer à votre Elasticsearch. On retrouve FileBeat permettant de gérer notamment les fichiers de logs, MetricBeat permettant de collecter des indicateurs et statistiques de machines (processeur, mémoire...) ou encore HeartBeat qui permet de surveiller la disponibilité d'applications web.
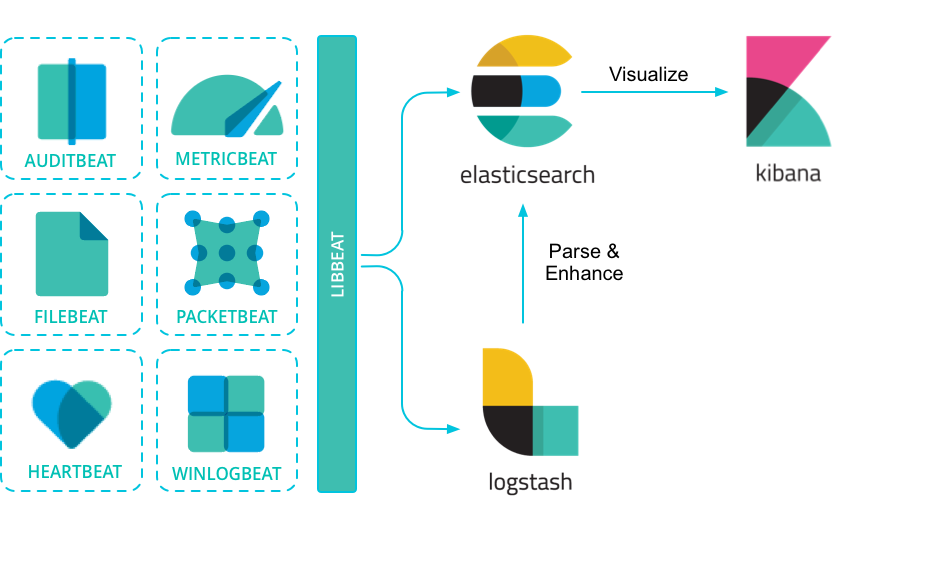
Ces modules ou agents peuvent être installés sur les différentes machines de votre architecture et envoyer leur données à un ou plusieurs cluster Elasticsearch.
FileBeat
FileBeat permet de configurer un ou plusieurs inputs correspondant aux différents types de logs que vous souhaitez gérer.
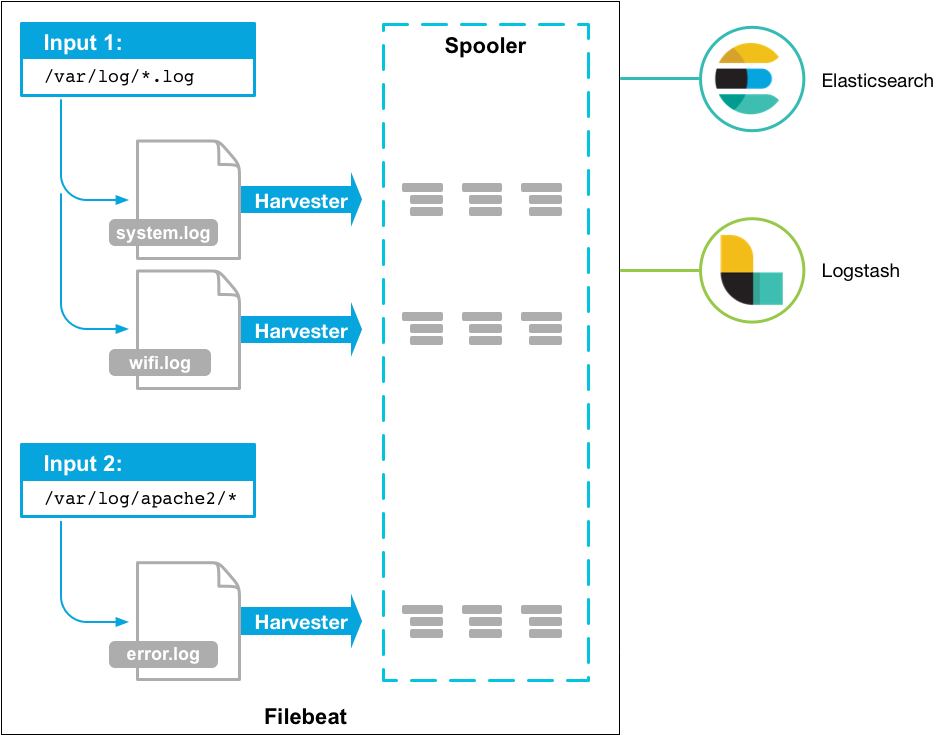
Lorsque des lignes sont ajoutées dans les fichiers surveillés par FileBeat, ce dernier les traite et transmet automatiquement à l'ouput configuré les lignes concernées.
MetricBeat
MetricBeat est un agent qui une fois installé sur les machines de votre architecture, permet d'envoyer périodiquement des métriques orientées système.
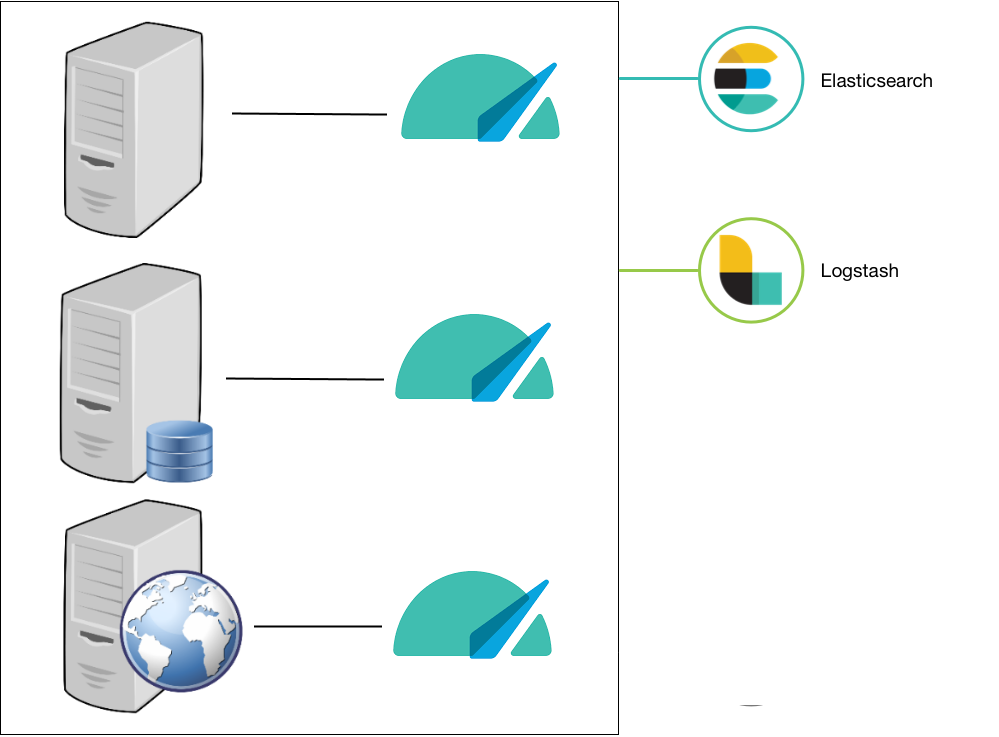
Il existe le module System, mais aussi des modules pour les serveurs Web (Apache, IIS, Nginx...), les services Cloud (AWS, Google Cloud, Azure) ou encore les serveurs de base de données (PostgreSQL, MySQL...).
Logstash
Logstash a pour but de récupérer des données dont l'origine et le format sont multiples, de les parser, éventuellement les transformer pour les envoyer vers une ou plusieurs sorties.
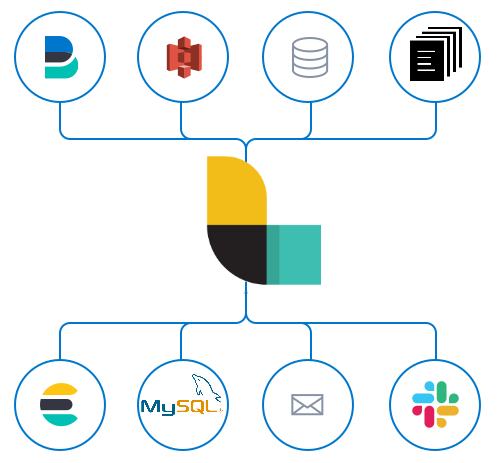
Le cas le plus courant est la récupération et l'analyse de fichiers de logs à envoyer dans un Elasticsearch. Mais les possibilités sont bien plus étendues.
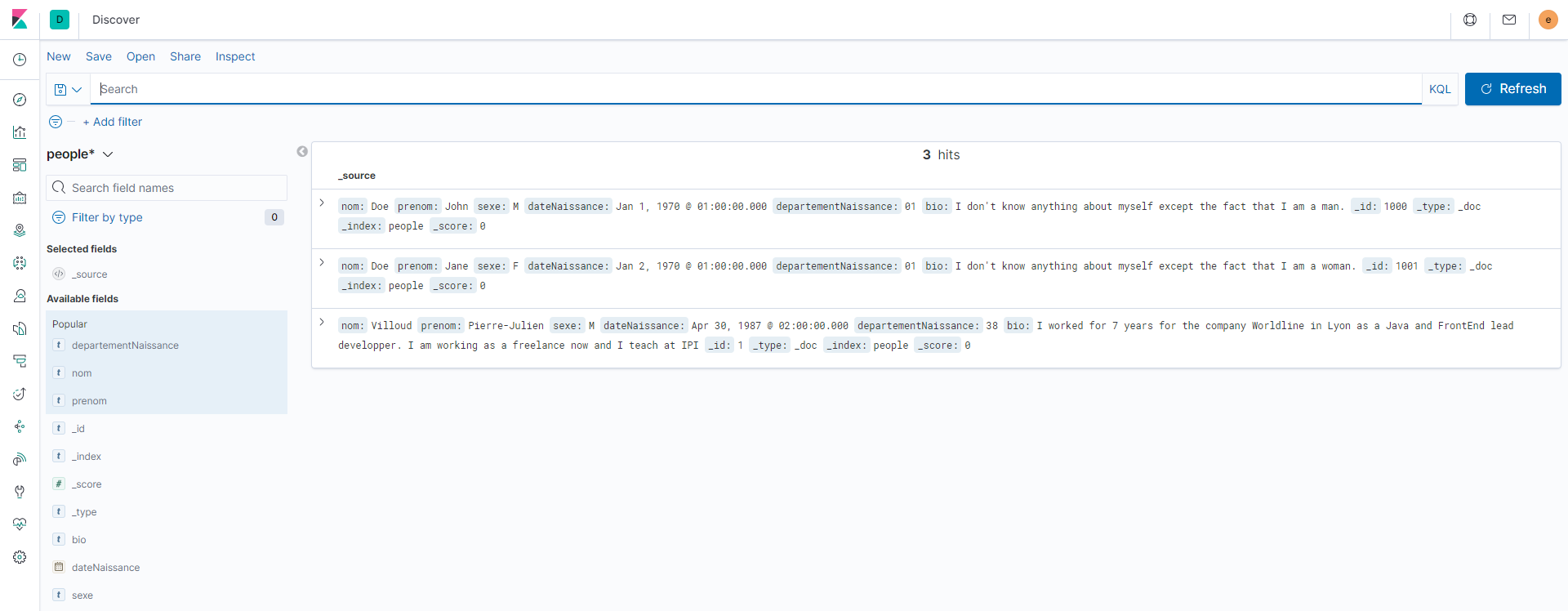
Discover
Discover permet l'exécution de recherches avec la syntaxe
KQL ou Apache Lucene.
Visualize
Visualize permet de représenter les données sous forme d'histogrammes, de courbes, de jauges afin des les rendre plus accessibles.
Paramétrage
Après avoir choisi le type de visualisation et la source de données (typiquement un ou plusieurs index), il faut configurer la visualisation. Dans l'onglet Data, on retrouve deux sections : Metrics et Buckets
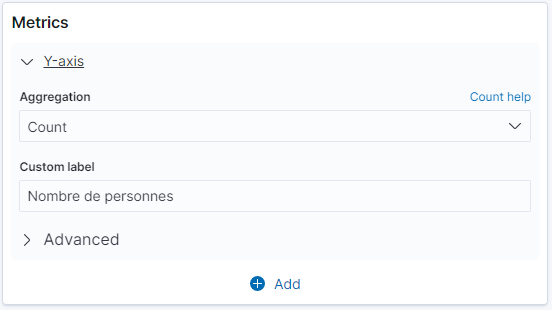
Metrics permet de définir quelles sont les informations qui seront affichées sur la visualisation.
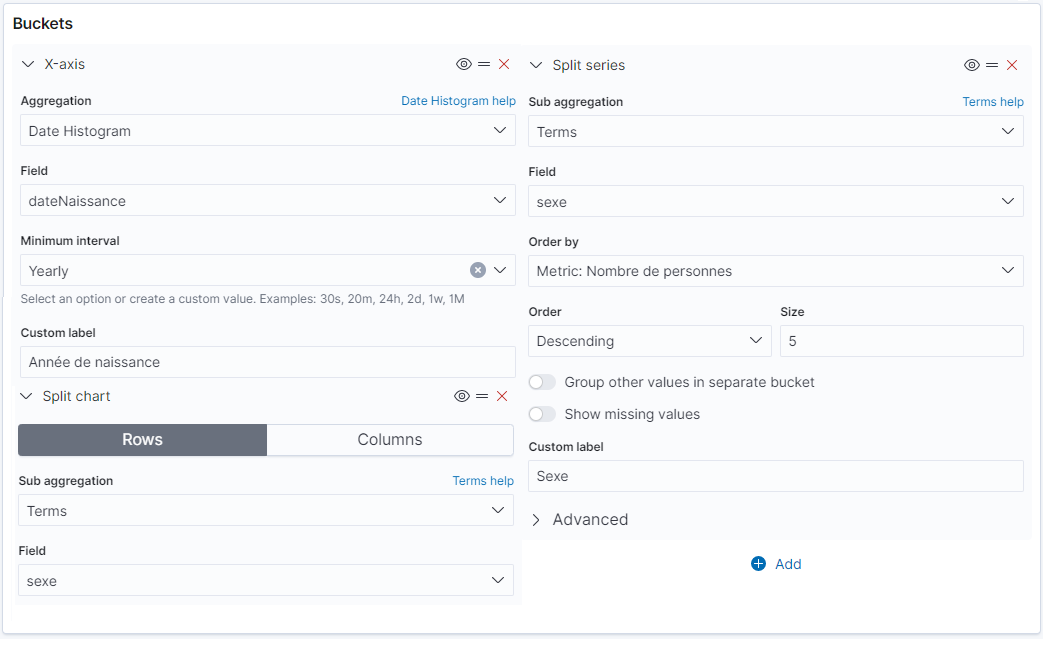
Buckets permet de définir comment on regroupe les données. On peut définir plusieurs séries (Split series) pour un diagramme et/ou avoir un diagramme pour chaque groupement (Split chart)
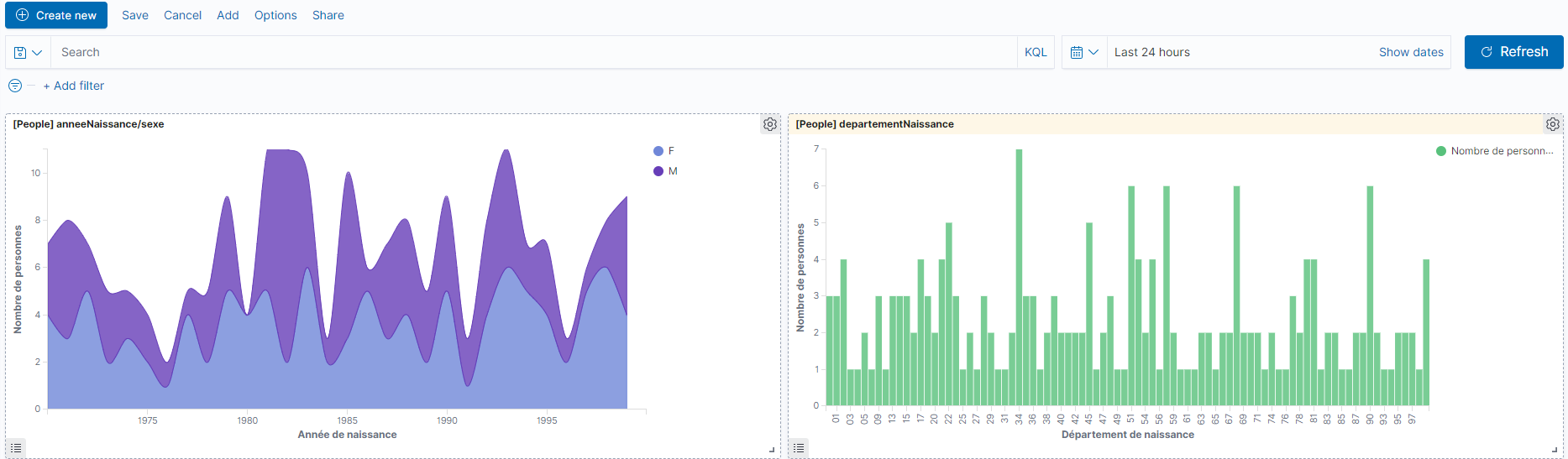
La visualisation peut être sauvegardée et insérée dans un Dashboard.
Dashboard
Outre le fait de regrouper des visualisations, le gros intérêt des dashboards est de pouvoir appliquer des filtres qui s'appliqueront automatiquement aux visualisations. De plus si l'on clique sur une série ou que l'on sélectionne une partie d'une visualisation, les documents sélectionnés seront automatiquement filtrés sur les autres visualisations.
Les dashboards peuvent également être mis à jour périodiquement.
Metrics
Metrics permet d'afficher les données issues de MetricBeat
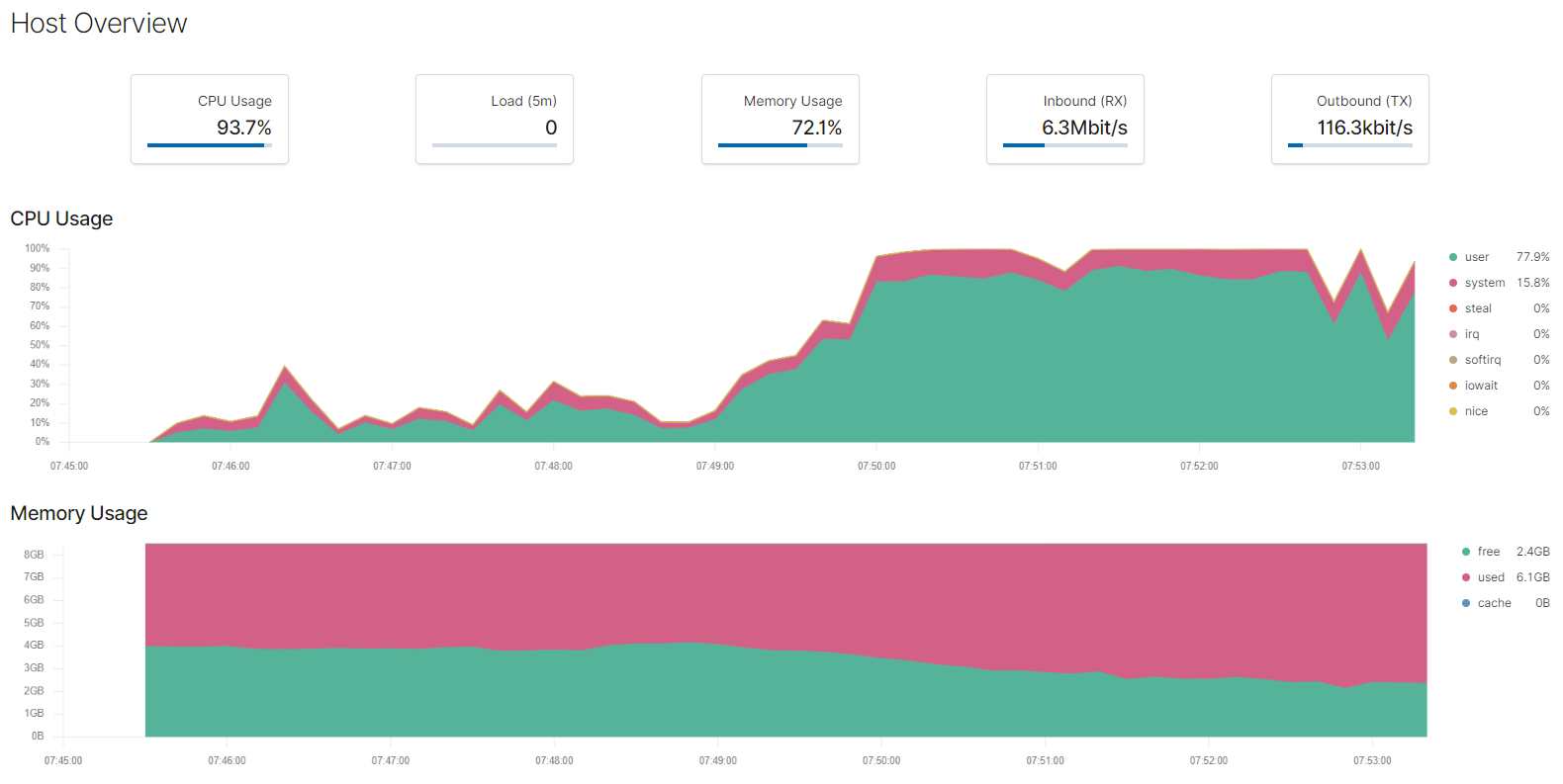
De nombreux dashboard spécialisés sont également disponibles avec Metricbeat et ses différents modules.
APM
APM est un ensemble d'outils de monitoring à adjoindre à votre application (Java, NodeJS, .NET, Ruby et bien d'autres) qui permet de récupérer en temps réel des métriques spécifiques à votre application.
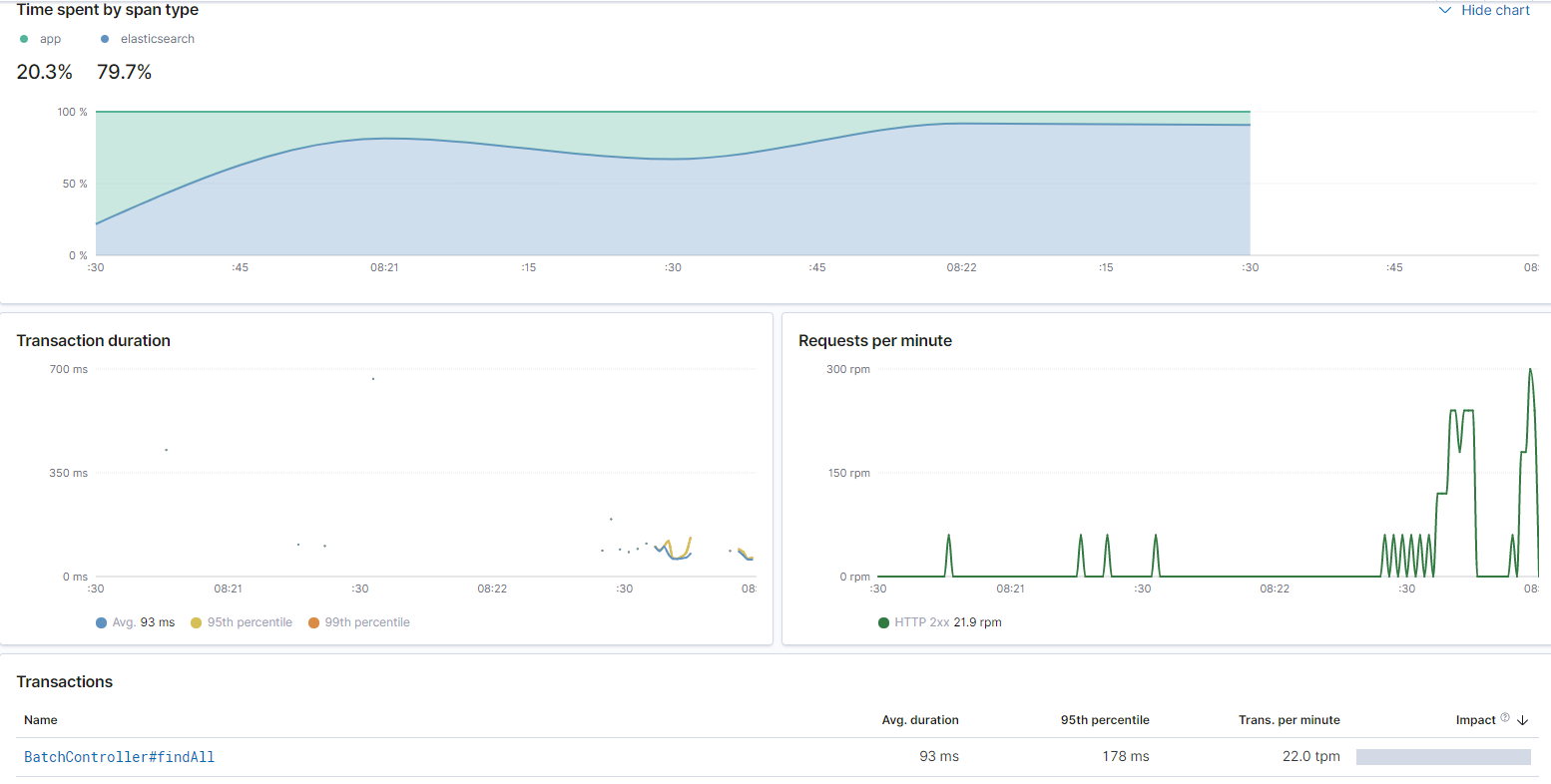
Toutes les précisions pour configurer APM pour Java ici ou directement sur APM.
Uptime
Uptime est une interface permettant de collecter les données envoyées par HeartBeat.
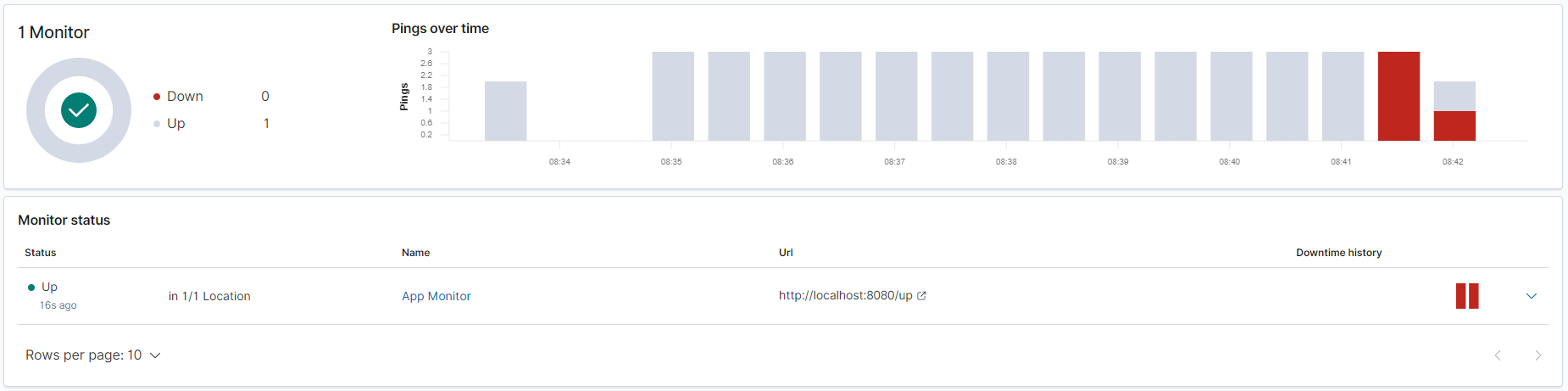
Conclusion
La suite Elastic permet de mettre en place relativement simplement un système complet, performant et scalable de surveillance technique et fonctionnel de vos applications afin de prévenir des éventuels problèmes ou de réagir rapidement et efficacement lorsqu'ils surviennent.